Move over AlphaGo: AlphaZero taught itself to play three different
Por um escritor misterioso
Descrição
DeepMind's new AI is worthy successor to the first program to beat a human at Go.

Why DeepMind AlphaGo Zero is a game changer for AI research
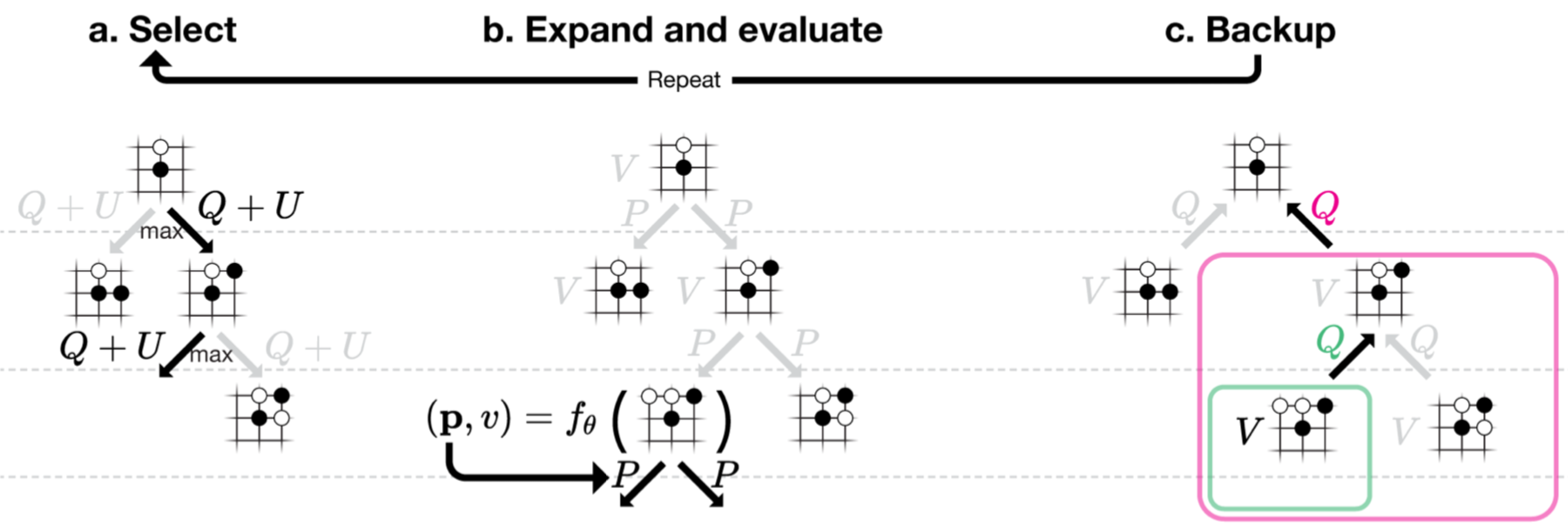
DeepMind's AlphaZero and The Real World
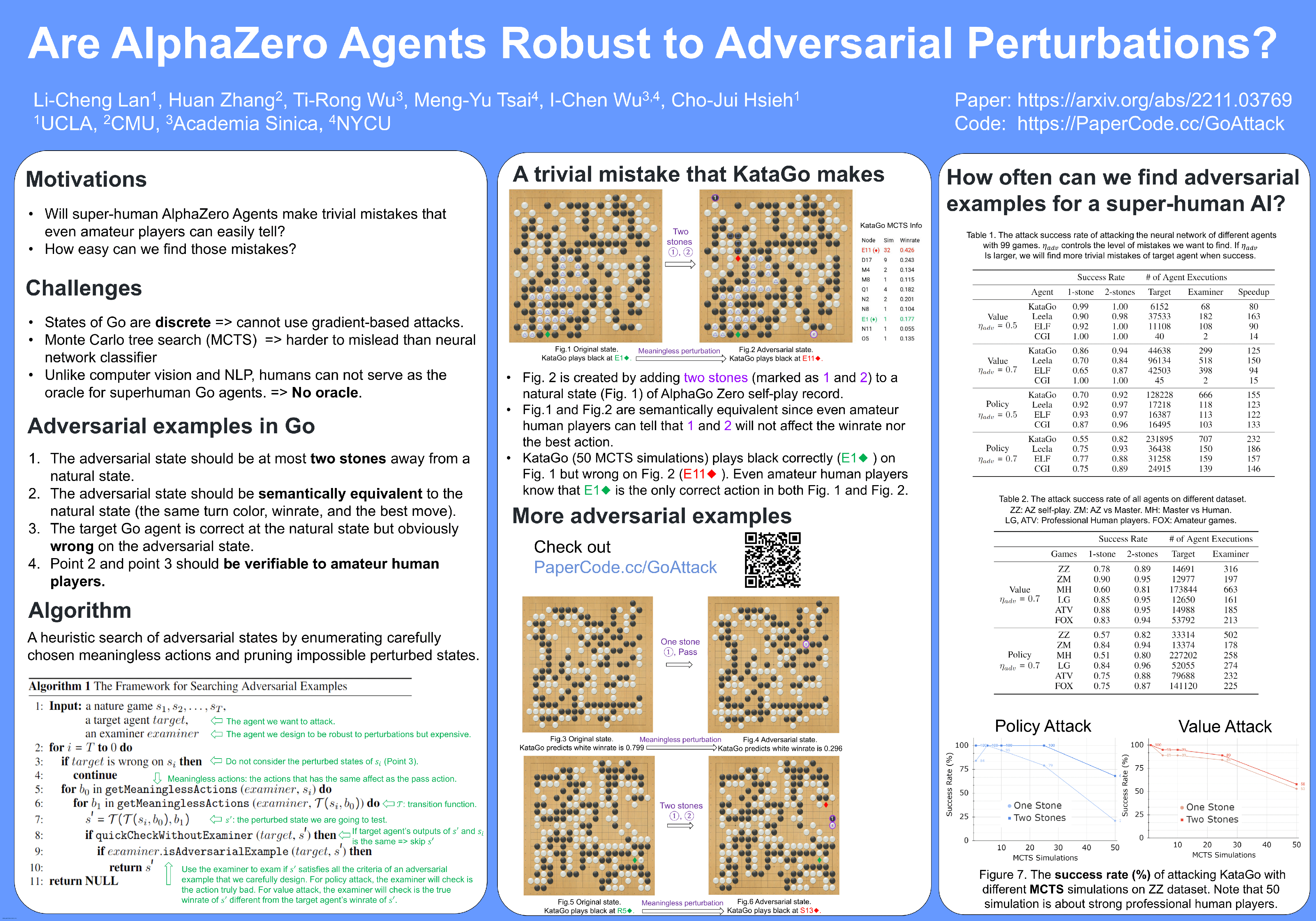
Self-play reinforcement learning in AlphaGo Zero. a The program plays a

A new computer program taught itself how to play chess, go and shogi - ABC News

DeepMind's Go playing software can now beat you at two more games
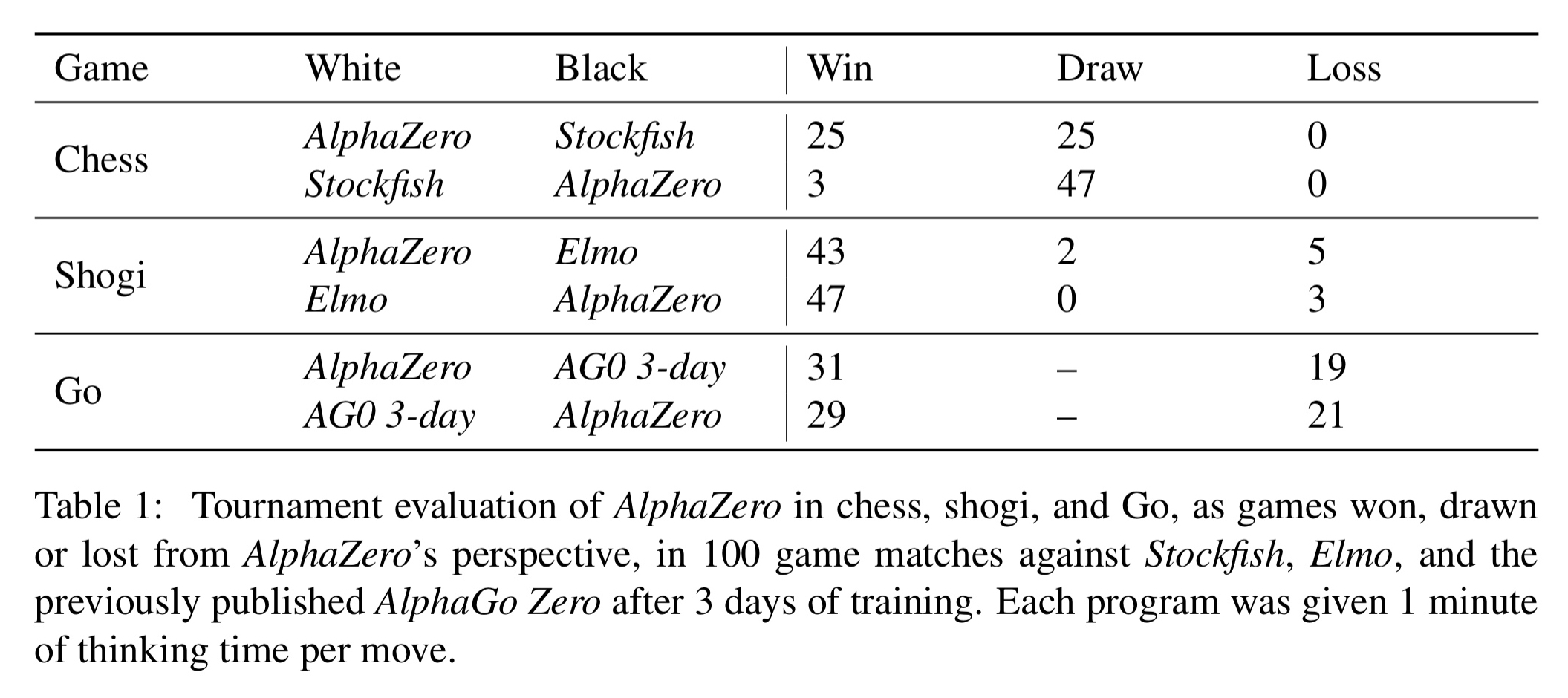
Mastering chess and shogi by self-play with a general reinforcement learning algorithm

How the Artificial Intelligence Program AlphaZero Mastered Its Games

Understanding AlphaZero Neural Network's SuperHuman Chess Ability - MarkTechPost
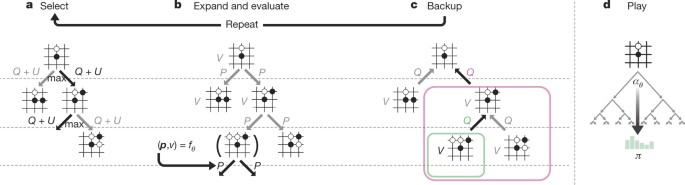
Mastering the game of Go without human knowledge

DeepMind's AI beats world's best Go player in latest face-off

AlphaGo taught itself how to win, but without humans it would have run out of time, Google
Will AlphaZero become smarter and smarter forever, if it plays chess against itself for unlimited times? - Quora
de
por adulto (o preço varia de acordo com o tamanho do grupo)