XQuAD Dataset Papers With Code
Por um escritor misterioso
Descrição
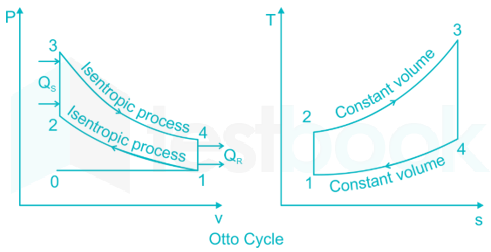
XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.

iFLYTEK & HIT Reading Comprehension Model Betters Humans, Tops
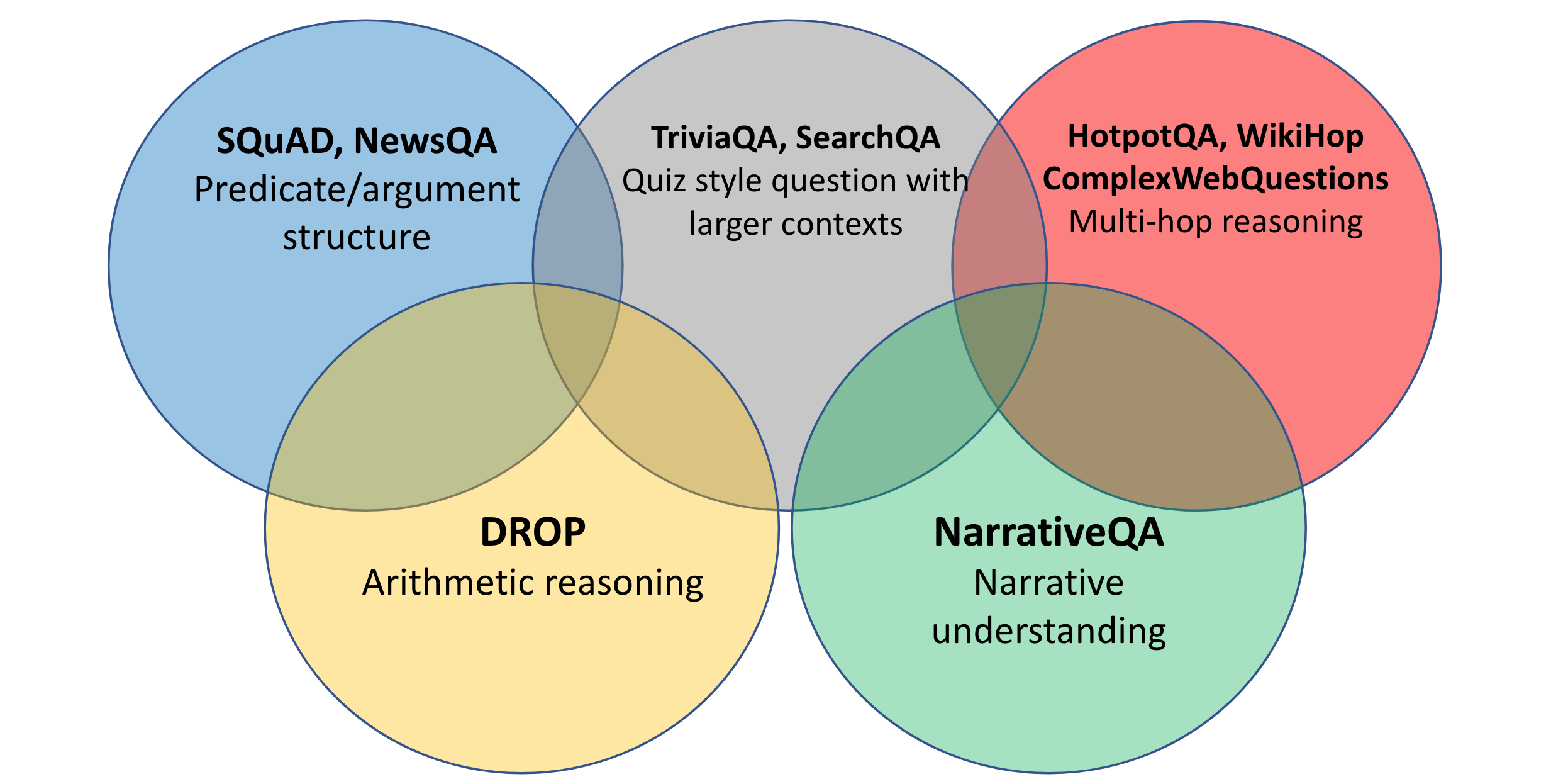
Multi-domain Multilingual Question Answering

Commonsense knowledge adversarial dataset that challenges ELECTRA
ACL Best Paper: Tricky Stanford DataSet Adds Questions That Don't
GitHub - google-deepmind/xquad

SQuAD2.0 Benchmark (Question Answering)

XQuAD Dataset Papers With Code

UAVVaste Dataset Papers With Code
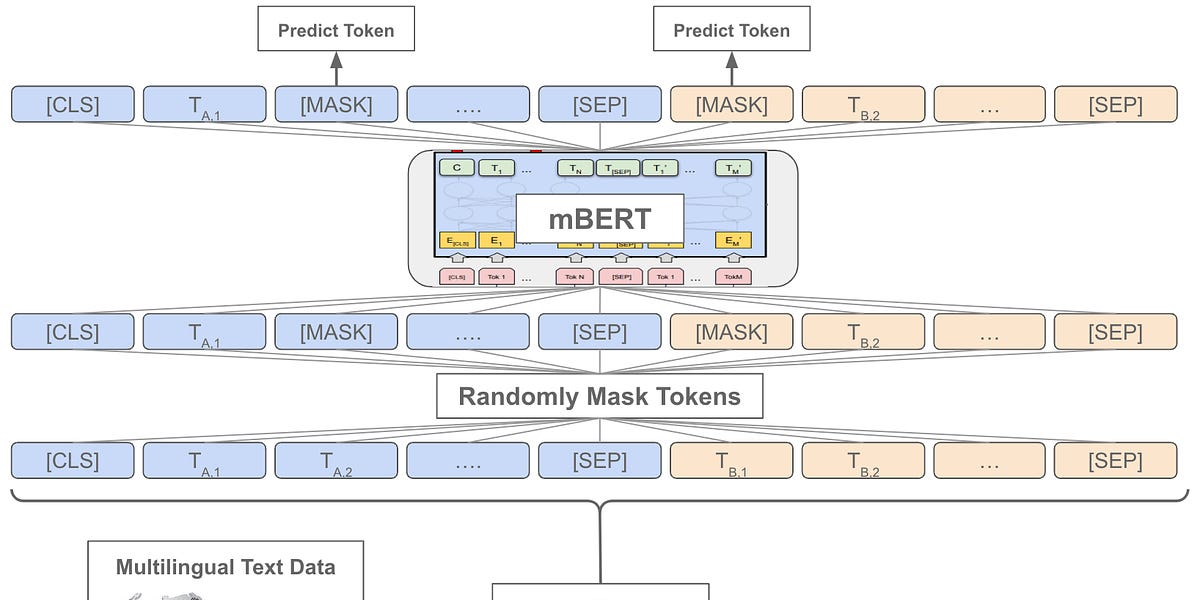
Many Languages, One Deep Learning Model

The Quick Guide to SQuAD. All the basic information you need to

How to Answer Questions with Machine Learning
de
por adulto (o preço varia de acordo com o tamanho do grupo)